Harnessing HPC power with {targets}
Jan 31, 2023
Develop local, sync, run on cluster
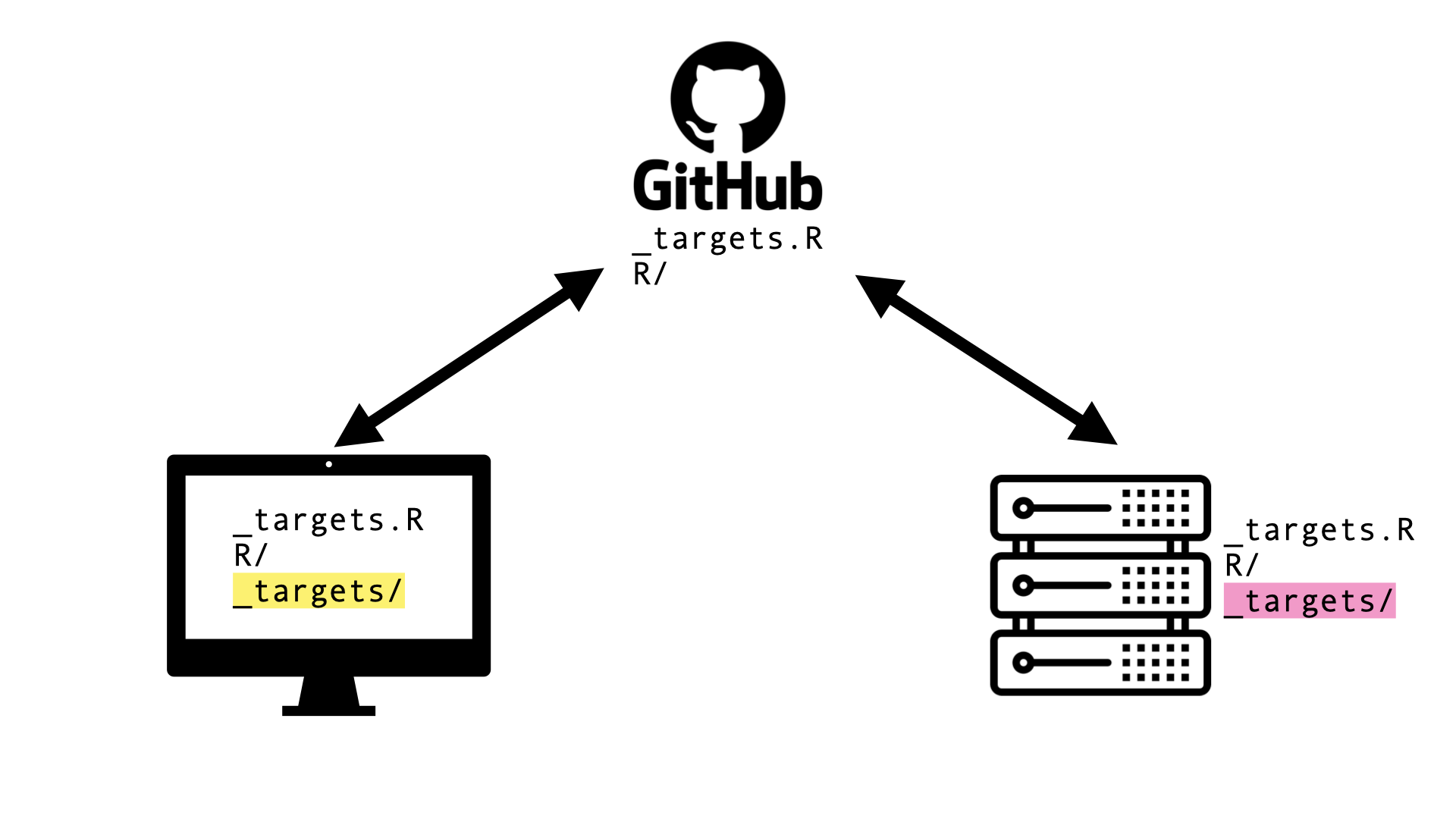
Cloud storage
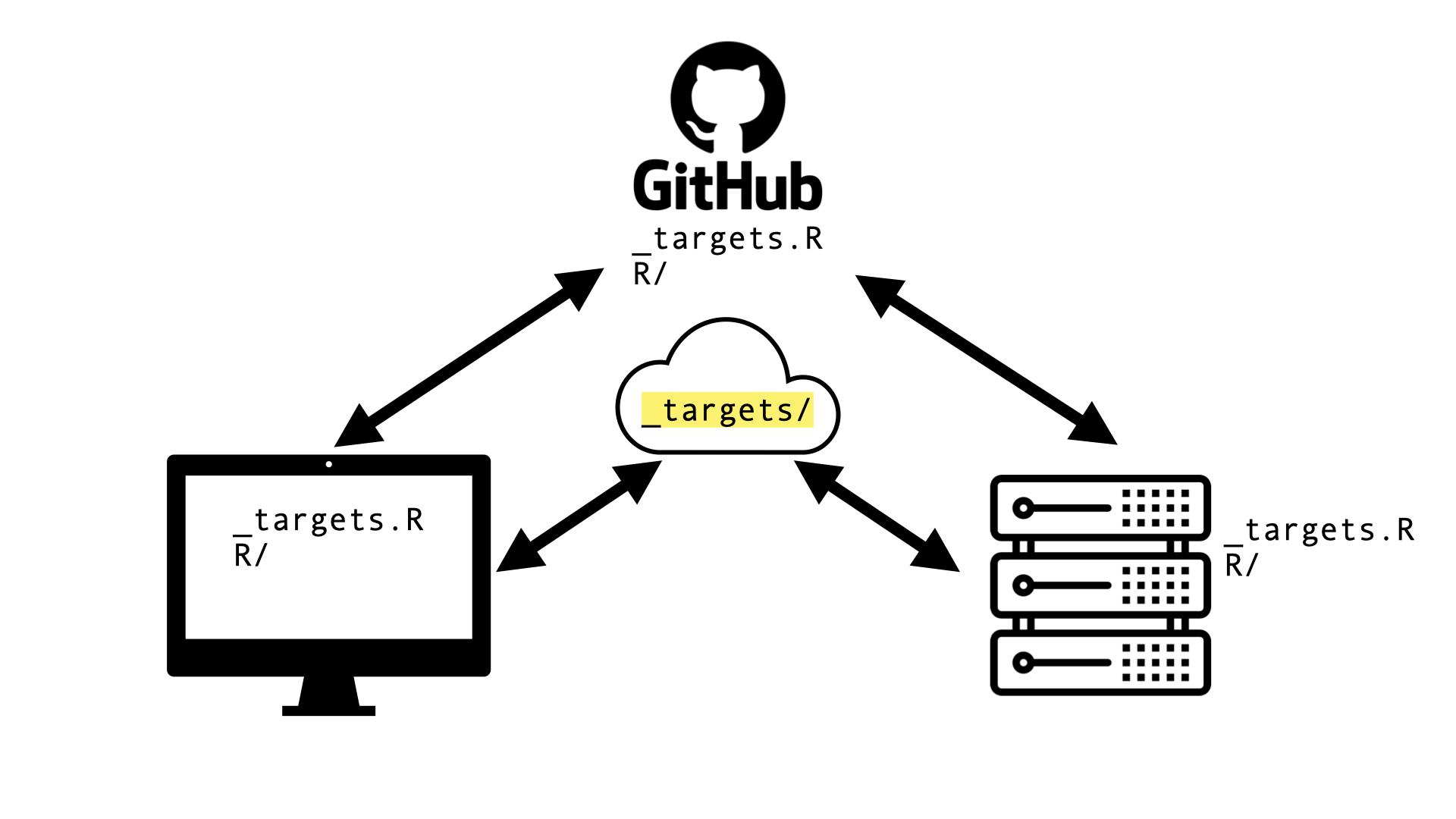
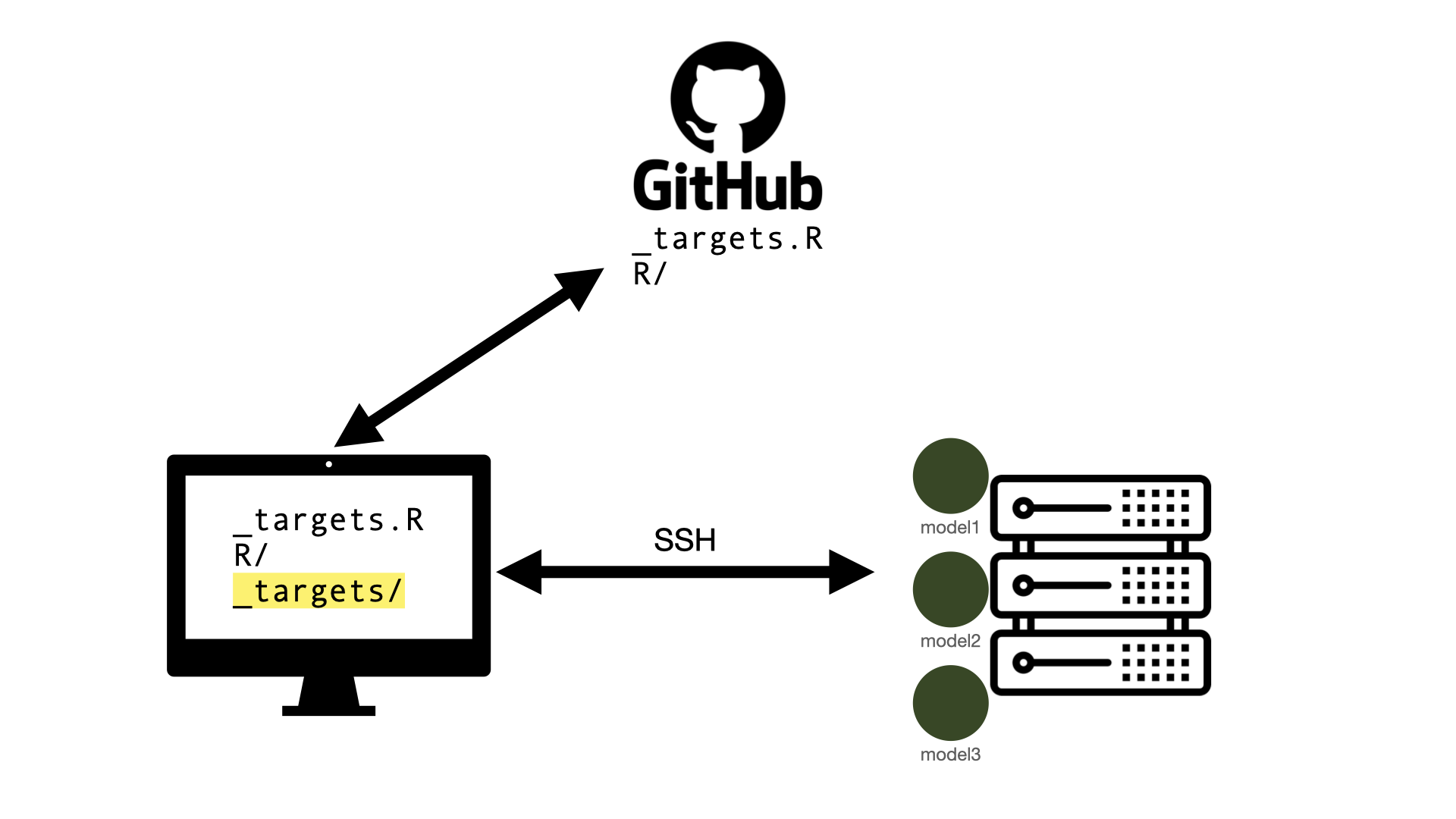
SSH connection
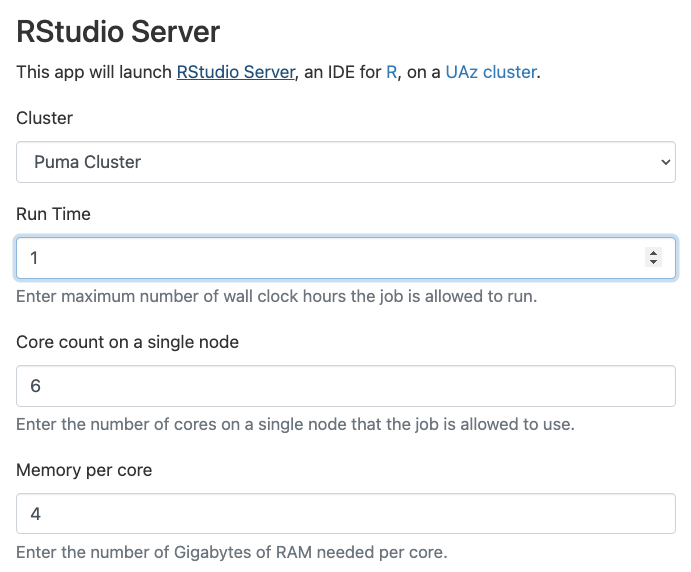
Lessons Learned: University of Arizona
- SSH connector requires an R session to run on login node—not possible at UA!
- Open On Demand RStudio Server
targetsauto-detects SLURM, but need to run as “multicore”
One last step: write it all down!
Template GitHub repo with setup instructions in README
Tell the HPC experts about it
University of Florida:
On the HPC: BrunaLab/hipergator-targets
Using SSH connector: BrunaLab/hipergator-targets-ssh
University of Arizona (WIP): cct-datascience/targets-uahpc